Introduction to Algorithm Analysis (2): Bubble Sort

(Here is Part1 and Part3)
In the first article of this series, we introduced the idea of algorithm analysis and explained briefly what it is and why it is important. Now, as promised, we shall consider a real world problem - that of sorting - and carefully analyze one of its many solutions
Bubble Sort
Even some who could be classified as laypeople might have heard of this algorithm and its reputation is not the best there is:
Immediately afterwards, the somewhat surprised interviewer exclaimed: "Come on, who told him this!", which is telling. Obama was obviously primed and whilst simply saying ""BubbleSort is bad" can get a quick laugh, in an actual job interview it doesn't quite cut it. Had he been pressed to explain, the situation might have looked radically different.
After reading this article, however, you will not only be able to justify the answer, you will also know why it was not the best he could have given.
But first, lets take a step back and have a look at what problem we are trying to solve and how we can go about doing so.
Sorting?
Sorting is any method of systematically arranging elements into an ordered sequence. There are a multitude of reasons why we would want to do that, ranging from better presentation for humans to more efficient processing by machines.
To do so, a desired result has to be well defined and usually we require at least what is called a strict weak ordering,
which is fancy math speak for being able to tell, given any two elements, if one should appear after the other.
Due to its apparent simplicity, the canonical example is putting simple integers into ascending order. That means, given a list like this:
[3,1,7,1729,9,90,42,4]
we wish to rearrange the elements, such that we end up with this:
[1,3,4,7,9,42,90,1729]
For now, to keep our algorithm as generically applicable as possible, all we are allowed to do is compare two elements and move them around in memory.
How does it work?
How does our algorithm accomplish that feat?
Remember that we can tell if one element should appear before another one? Bubble Sort uses that fact and does the most trivial thing imaginable: It walks through all elements and, one by one, compares each with its successor. If their relative positioning is wrong, it swaps.
Here is simplified pseudocode illustrating the idea, followed by a very illuminating visualization:
while not sorted
for i=0 to length-1
if element[i]>element[i+1]
swap elements i and i+1
As you can see, after the first iteration the biggest element was moved all the way to the end. Followed by the second biggest in the next iteration and so on. This property is what gave BubbleSort its catchy name. One after other, like bubbles in water, the biggest elements rise to the top.
Analysis
Alright! Now that we have and understand our algorithm, how can we tell if it is actually suitable for sorting a million or billion elements? The most straightforward approach would obviously be to simply try it. Code up a solution, create a few random permutations of 1...1000000000, run and measure. Unfortunately, you'll quickly realize that doing so is not exactly feasible and we might have to waste a lot of resources and wait for a very long time to get any results.
What we could do instead is measure for some smaller input sizes and then, based on some general idea of how our runtime will grow with increasing input size, extrapolate to a billion.
This notion of how some resource usage grows based on some property of the input is what algorithm analysis is all about. If, for instance, our runtime doubles with each doubling of input size, we call the algorithm linear or say it's runtime is O(n), as it can be expressed as a linear equation:
runtime = time_for_size_1 * n
Is BubbleSort linear? Let's find out:
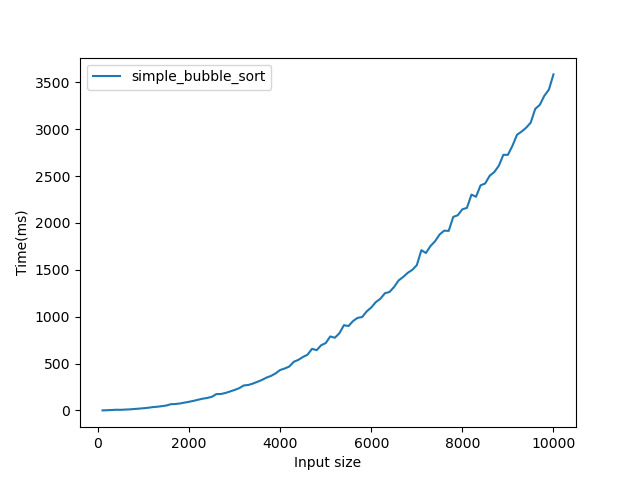
That does not look linear(it would have to be a straight line). From just a few measurements we cannot be sure, as we might have hit some special cases. This is just empirical data and we can do better: Look at the source and count how many steps are taken. Here is the relevant fragment:
for(std::size_t i=0;i<data.size();++i)
{
for(std::size_t j=0;j<data.size()-1;++j)
{
if(data[j]>data[j+1])
std::swap(data[j],data[j+1]);
}
}
I replaced the "not-sorted" used in pseudo code by doing n passes. As each pass guarantees one more element is in the right place, everything is sorted in the end.
But wait! What do we count? Is j+1 as expensive as swap? Does it matter? That depends on the problem analyzed and should be chosen carefully. Sometimes, even some mathematical operators are more equal than others.
A useful metric for comparison based sorts is counting their basic building blocks, i.e. number-of-comparisons + number-of-swaps.
Great! In so doing, we arrive at another impasse: The outer loop runs n times, for each of those runs the inner one is executed n-1 times. Each of those contains a comparison, so we have n*n-1 comparisons. What about swaps? They depend on the data, so should we assume the branch to be taken or not?
Without any further knowledge, we have to assume the worst: Some malicious actor who knows every single step of our code constructs the sequence on the fly to always force us to take the longest possible route through our code.
For our case, this means every branch in the first round is taken(n-1), implying the first element was bigger than all others. Afterwards, no matter how adversarial the sequence, the last comparison must be false to stay consistent. All others may still be true, so the branch is taken n-2 times now. In total, we take the branch n-1 + n-2 + n-3... times and Gauss taught us this is equal to (n^2-n)/2. The dominant(largest) term is still quadratic, so whilst the total number of swaps is smaller than that of comparisons, they grow at the same rate.
Observing the properties mentioned above, we can construct an instance representing this worst case:
[9,8,7,6,5,3,1]
In fact, every descending sequence is a worst case.
Can we do better? Yes, just not asymptotically so:
for(std::size_t i=0;i<data.size();++i)
{
bool swapped = false;
for(std::size_t j=0;j<data.size()-1-i;++j)
{
if(data[j]>data[j+1])
{
std::swap(data[j],data[j+1]);
swapped = true;
}
}
if(!swapped)
break;
}
The inner loop now skips the already correct end and we break the outer loop once we are sorted.
The worst case for swaps stays the same, but the number of comparisons is now equal to it. More interesting, however, is what happens in the best possible situation:
Assuming we ourselves could chose the sequence however we please, how low can we force the number of operations? We can decide the branch will never be taken, implying the first element is smaller than the second, which is smaller than the third and so on. swapped will never be set to true and we break after just a single pass over the data! For a best case instance - any already sorted sequence - the runtime is linear.
As such, we arrive a result: BubbleSorts worst case is O(n^2), its best case O(n).
Here is one last plot, showing just how accurate our estimate has become(and how rare the best case is):
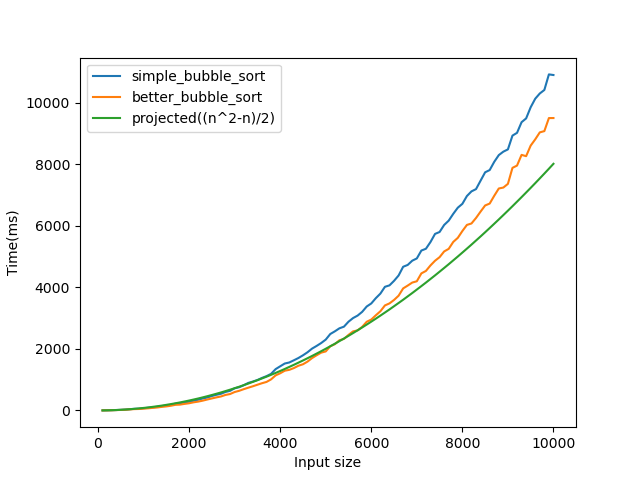
Conclusion
And thus, we return to the question posed in the beginning. The best reply is neither "not BubbleSort", nor even radix sort nor any other algorithm. The best reply is a followup question: What do we know about the data? Maybe, just maybe, we know that only one element in there is wrong. If so, even bubble sort might not be the worst idea. And now you understand why :)




